版权声明:本文转载于https://zhuanlan.zhihu.com/p/628494696,已征得作者同意
未经允许不得二次转载,如有需要请私信作者。
书接上回,
在开始讲解之前,我们先说个梗,
open AI,从这个名字就能看出来,这个是开源的。
但是目前来说,gpt官网不仅不有公开,甚至对外公开的API也只有一个现成的。完全是一个黑盒。背弃了公开的这个原则。
马斯克甚至公开炮轰open ai。笑。
那么到底open ai的官方文档,干了什么天怒人怨的事情呢?
我们就来详细分析一下
2.chatGPT-4官方技术文档讲解
论文的链接如下:GPT-4 Technical Report
GPT-4 Technical Reportarxiv.org/pdf/2303.08774.pdf
或者可以在官网当中获取:
GPT-4openai.com/research/gpt-4
我们先来看看摘要:

在摘要中,明确了GPT的技术构成为:大模型,多模态,可以接受图像和文本的输入,输出位文本,这一句基本上是定性。
第二句表明了初步认为GPT-4已经很厉害了,很拟人了,判断的标准是什么呢?是他可以通过很多类人的考试,表现出了“人类级别的表现”,而且在这些考试当中,基本上处于前十的这个表现。
第三句表明了,GPT-4是一个基于transformer的模型,而且是基于预训练的模型,主要行为方式是通过预测下一个文本类token,来实现推理的。
剩下的就是在夸自己。
吐槽的点:其实我们更关心的是你提升了多少精度,用的什么模型,什么数据量级,什么GPU型号,什么算力集群,在这个摘要,乃至整个论文当中,都没有提及。
0 Introduction
open ai公司创建了 GPT-4,这代表着 OpenAI 在扩大深度学习规模方面的最新里程碑。
GPT-4 是一个大型多模态模型,它接受图像和文本输入并输出文本。尽管在许多现实场景中它可能不如人类能力强,但在各种专业和学术基准测试中展现出人类水平的表现。官方举的例子是GPT-4在模拟的律师考试中的得分约为测试者的前 10%,而 GPT-3.5 的得分则约为后 10%。因为在国外的话,律师考试含金量比较大。。
open ai 提到:在过去两年里,他们重建了整个深度学习栈(这里我理解为是一个计算集群),并与 Azure(一家公司) 共同设计了一台超级计算机(集群)。
顺便吐槽下,这也是很多人认为GPT-3.5是大力出奇迹的部分原因。
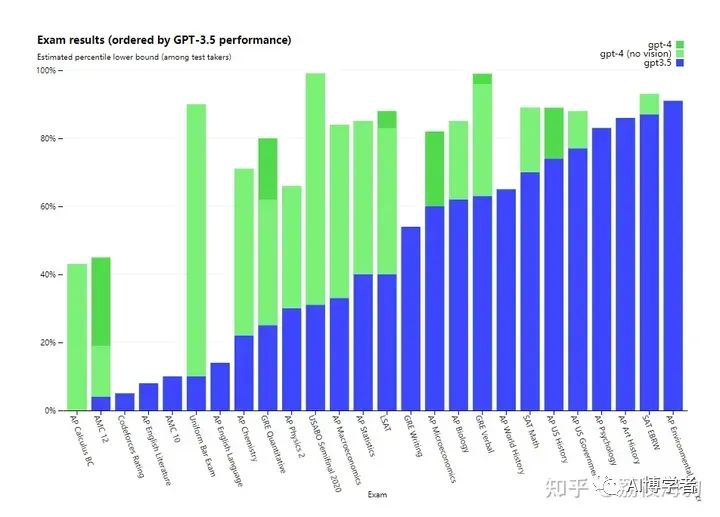
通过统计图可以看出,基本上在大部分领域,gpt-4的表现都优于gpt-3.5.这也是印证了前面的话:gpt-4有了类人的表现。
1 视觉输入
GPT-4可以接受包含文本和图像的提示,用户可以指定任何视觉或语言任务。具体而言,它可以根据交错的文本和图像输入生成文本输出(自然语言、代码等)。在包括文本和照片、图表或屏幕截图在内的各种领域,GPT-4在仅有文本输入的情况下展现出的能力与图像和文本交替输入的情况类似。此外,它还可以采用针对仅有文本的语言模型开发的测试时间技术,包括少样本和思维链提示。但是目前实际情况中,图像输入仍然是研究预览,不对公众开放。
我们来看看实例demo

Q:请问这幅图内有什么好笑的事情?
A:
The image shows a package for a "Lightning Cable" adapter with three panels.
Panel 1: A smartphone with a VGA connector (a large, blue, 15-pin connector typically used for computer monitors) plugged into its charging port.
Panel 2: The package for the "Lightning Cable" adapter with a picture of a VGA connector on it.
Panel 3: A close-up of the VGA connector with a small Lightning connector (used for charging iPhones and other Apple devices) at the end.
The humor in this image comes from the absurdity of plugging a large, outdated VGA connector into a small, modern smartphone charging port.我们从gpt-4的回答当中能看出,关于图像理解这块他们还是比较强的,模型可以很快的识别图中的内容,而且能够定义到“好笑”的这个梗-->这么大的VGA插头,居然是这么小的充电器,这种落差幽默。
2 训练过程
与之前的GPT模型一样,GPT-4基础模型是通过训练来预测文档中的下一个单词,并使用公开可用的数据(互联网数据)以及已经获得许可的数据(购买的数据集)进行训练。这些数据是包括数学问题的正确和错误解法、弱和强推理、自相矛盾和一致陈述的网络规模数据集,代表了各种意识形态和思想的巨大多样性。
因此,当受到问题的提示时,基础模型可能会以各种方式回答,这可能与用户的意图相差甚远。为了在安全边界内使其符合用户的意图,open ai使用强化学习与人类反馈(RLHF)来微调模型的行为。
结论
只要神经网络的复杂性和训练样本的多样性超过一定规模,就会有抽象的推理结构在神经网络里突然自发涌现出来。符合我的认知规律------量变导致质变。
今天的大语言模型已经在很多方向上确定无疑地迈过了某个重要的阈值。这使得整个关于模型能力的认知都需要迅速重估。
人类自己的进化史上语言的诞生被认为是个重要的节点,这意味着大脑的复杂程度决定性地超越了此前的近亲,然后语言又反过来给大脑的发育带来巨大的压力,迫使它走上了一条所有其他动物都没走过的演化道路。
今天很可能是 AI 演化史上的类似时刻。
欢迎大家讨论,留言,交流,如果有兴趣了解更多,我们一起共同进步。