

写在前面
AI催生热门职业 prompt engineer,前段时间硅谷已经开出了年薪33万美元的高薪,国内吹起了一波Prompt学习风,市面上充斥着各种指南教你如何生成完美的提示词,而且也有些在网上卖提示词,一个提示词要价100-200元,真是利用老百姓的焦虑和好奇心妥妥的割韭菜。

OpenAI官方估计也看不下去啦,所以联合DeepLearning.AI创始人吴恩达在4月27日推出面向开发者的 ChatGPT提示工程英文课程,小编借着Notion AI的翻译功能做成中文版,并在微信视频号发布了中文字幕短视频系列课。
因此,学习知识就学基础知识,而且自上而下的学习效率最高,也能快速得其全貌以及掌握ChatGPT的能力边界;自下而上的学习好比盲人摸象方式学习,摸到大象腿可能以为是房柱子,不仅效率低还容易歪曲事实。
“BORE”提示词分析法
有网友总结一套“BORE”分析法设计chatGPT prompt,包含了清晰明确指令以及迭代思想的原则,即不要指望通过一个指令搞定所有问题。
| 步骤 | 说明 | 样例:自动驾驶卡车试乘报告框架 |
| 阐述背景 B (Background) | 说明背景,为 chatGPT 提供充足信息 | • 我们公司研发自动驾驶卡车系统。我们的车辆已经拥有在特定道路上完全靠自己驾驶的能力,但是目前车上仍有司机作为安全员,自动驾驶系统会辅助司机驾驶,帮助卡车司机开车更轻松,更安全。 ◦ 点明业务目标,提供基本背景 • 作为一个产品经理,你需要用敏锐的目光去发现改进点,并提供建议。 ◦ 让 chatGPT 进入角色,缩小任务范围 • 现在你要去试乘我司的产品:一款自动驾驶卡车。这辆卡车上有司机,它将在一条主要是高速的长途货运路线上装载货物运营。 ◦ 进一步告知当前业务的细节 |
| 定义目标 O (Objectives) | “我们希望实现什么” | • 请为我提供一个试乘体验报告框架模板。 ◦ 设定明确的目标,“chatGPT 需要产出的内容是什么” |
| 定义关键结果 R (key Result) | “我要什么具体效果” | • 模版要涵盖产品体验的不同方面 ◦ 明确范围上的要求 • 使用逻辑严密,清楚的语言 ◦ 明确语言上的要求 • 有优雅,清晰,易于理解的结构。 ◦ 明确结构上的要求 |
| 试验并改进 E (Evolve) | 三种改进方法自由组合 1. 改进输入:从答案的不足之处着手改进背景 B,目标 O 与关键结果 R 2. 改进答案:在后续对话中指正 chatGPT 答案缺点 3. 重新生成:尝试在 prompt 不变的情况下多次生成结果,优中选优 | • 如果对 chatGPT 生成的答案不满意,可能是 ◦ 情况 1:指令给得不够清楚 ▪ 改进提示 (输入内容) • 改进背景 B (Background):检查提供给 chatGFT 的信息是否充足 • 改进目标 O (Objectives):检查是否明确说明 “要生成什么东西” • 增加/修改关键结果 R (key Result):若 chatGPT 答案没有体现你想要的东西,可以在关键结果 R 中补充说明要求。 ◦ 情况 2:chatGPT 干得不好,或回答有错误 1. 改进答案:在接下来的对话中指出答案中的错误与不足,让它重新回答 ◦ 情况 3:运气不好,碰上糟糕的输出 1. 重新生成:相同 prompt(输入)让 ChatGPT 多生成几次,优中选优。• 三种方法需要组合起来,重复、多次使用,才可以得到满意答案。 |
一些tips:
若要使用中文回复,请在最后一句插入条件 请用中文回答。为了保持描述的精确性,提示词建议使用英文,毕竟chatgpt以英文语料训练为主,最后一句的定制条件可以使用任何语言,包括中文。 不要用 ChatGPT 解答数学问题,出错概率达 50%,可以配合COT模式使用,即step by step。 不用用ChatGPT查询文献资料,基本上胡编的文献链接。 若chatgpt回答内容不完整,请输入“ 请继续”,chatgpt会继续补齐剩余内容。若ChatGPT回答的内容未按照要求输出,可以质疑给的结果“ 你未按照刚刚提的***要求生成,请重新回答”等。
开始学习啦
虽然官方的课程内容是面向开发者,但是原理与在ChatGPT 网页版使用的原则其实是一模一样的,以下内容中的示例都是在界面版功能实现。官方课程总时长1.5小时,总共9节,小编分别上传了9期内容到微信视频号,章节内容配合视频号内容一起学习效果更佳!接下来内容有些长,偶尔有些枯燥,但是坚持看完你一定有收获。
1. 介绍
欢迎来到这个针对开发人员的ChatGPT提示工程课程。我很高兴能和Isa Fulford一起教授这门课程。她是OpenAI的技术人员,并建立了流行的ChatGPT检索插件,大部分工作是教授人们如何在产品中使用LLM或大语言模型技术。她还为OpenAI cookbook做出了贡献教人提示。很高兴能和你在一起。我很高兴能在这里与大家分享一些提示最佳实践。
因此,在互联网上有很多有关提示的材料,如30个每个人都必须知道的提示。其中很多都集中在ChatGPT网络用户界面上,许多人正在使用它来完成特定的、经常是一次性的任务。但我认为LLM大语言模型作为开发人员的强大之处在于使用API调用到LLM,以快速构建软件应用程序。我认为这仍然是被低估的。事实上,我们在AI Fund的团队,这是[DeepLearning.AI](http://deeplearning.ai/)的姊妹公司,一直在与许多初创公司合作,将这些技术应用于许多不同的应用程序,并且看到了LLM API可以使开发人员能够非常快速地构建。因此,在这个课程中,我们将与您分享一些您可以做的可能性以及如何做到这一点的最佳实践。有很多材料要覆盖。
首先,您将学习一些软件开发的提示最佳实践。然后,我们将涵盖一些常见的用例,如概括、推断、转换、扩展。然后,您将使用LLM构建聊天机器人。我们希望这将激发您的想象,让您构建新应用程序。
因此,在大语言模型或LLM的开发中,大致有两种类型的LLM,我将它们称为基本LLM和指令调整LLM。因此,基本LLM已经训练出根据文本训练数据预测下一个单词的能力,通常是在互联网和其他来源的大量数据上进行训练,以确定下一个最可能的单词是什么。因此,例如,如果您要提示这是从前有一只独角兽,它可能会完成这个任务,即它可能会预测接下来的几个单词是与所有独角兽朋友一起生活在魔法森林中。
但是,如果您要提示这是法国的首都是什么,那么根据互联网上的文章可能是,基础LLM可能会完成这个任务,即法国最大的城市是什么,法国的人口是多少,因为互联网上的文章可能很可能是关于法国国家测验问题的列表。
相比之下,指令调整LLM,这是LLM研究和实践的很大动力,已经训练出了遵循指令的能力。因此,如果您要问它法国的首都是什么,它更有可能输出类似法国的首都是巴黎的东西。因此,指令调整LLM通常的训练方式是从训练了大量文本数据的基础LLM开始,而进一步训练则是通过输入和输出是指令和良好尝试遵循这些指令来微调它,然后通常使用一种称为RLHF的强化学习来自人类反馈来进一步改进系统,使其更能够有帮助并遵循指令。因为指令调整LLM已经被训练成有帮助、诚实和无害,所以它们比基础LLM更不可能输出有问题的文本,例如有毒的输出。许多实际使用场景已经转向指令调整LLM。您在互联网上找到的一些最佳实践可能更适合基础LLM。但是对于今天的大多数实际应用程序,我们建议大多数人专注于指令调整LLM,因为它们更易于使用,并且由于OpenAI和其他LLM公司的工作,它们变得更加安全和更加一致。因此,本课程将重点介绍指令调整LLM的最佳实践,这是我们建议您用于大多数应用程序。
在继续之前,我想感谢来自OpenAI和[DeepLearning.ai](http://deeplearning.ai/)的团队为Isa和我提供的材料做出了贡献。我非常感谢来自OpenAI的Andrew Main、Joe Palermo、Boris Power、Ted Sanders和Lillian Weng的工作。他们非常参与我们的头脑风暴材料,审查材料,为这门短期课程准备课程大纲。我也感谢Geoff Ladwig、Eddy Shyu和Tommy Nelson的深度学习方面的工作。因此,当您使用指令调整LLM时,请考虑向另一个人发出指令,例如一些聪明但不知道您任务具体细节的人。因此,当LLMs不起作用时,有时是因为指令不够清晰。例如,如果您要说,请给我写一些关于艾伦·图灵的东西。此外,清楚指定您是否希望文本专注于他的科学工作,还是个人生活,或者他在历史上的角色或其他内容,并且如果您指定了文本的语气,应该采用像专业记者写的语气吗?还是它更像是您给朋友写的随意笔记,希望LLM可以生成您想要的?当然,如果您想象自己询问,比如让一个新毕业的大学生为您执行此任务,如果您甚至可以指定他们应预先阅读哪些文本片段来撰写有关艾伦·图灵的文本,那么这将更好地为这个新的大学毕业生设置成功,为您执行这项任务。因此,在下一个视频中,您将看到如何清晰和具体的示例,这是提示词的一个重要原则。您还将学习提示的第二个原则,即给LLM(大语言模型)思考的时间。因此,让我们进入下一个视频。
2.提示指南
2.1 两个基本原则
原则一:编写清晰、具体的指令
你应该通过提供尽可能清晰和具体的指令来表达您希望模型执行的操作。这将引导模型给出正确的输出,并减少你得到无关或不正确响应的可能。编写清晰的指令不意味着简短的指令,因为在许多情况下,更长的提示实际上更清晰且提供了更多上下文,这实际上可能导致更详细更相关的输出。
策略一:使用分隔符清晰地表示输入的不同部分,分隔符可以是:```,"",<>,
你可以使用任何明显的标点符号将特定的文本部分与提示的其余部分分开。这可以是任何可以使模型明确知道这是一个单独部分的标记。使用分隔符是一种可以避免提示注入的有用技术。提示注入是指如果用户将某些输入添加到提示中,则可能会向模型提供与您想要执行的操作相冲突的指令,从而使其遵循冲突的指令而不是执行您想要的操作。即,输入里面可能包含其他指令,会覆盖掉你的指令。对此,使用分隔符是一个不错的策略。
策略二:要求一个结构化的输出,可以是 Json、HTML 等格式
第二个策略是要求生成一个结构化的输出,这可以使模型的输出更容易被我们解析,例如,你可以在 Python 中将其读入字典或列表中。
策略三:要求模型检查是否满足条件
如果任务做出的假设不一定满足,我们可以告诉模型先检查这些假设,如果不满足,指示并停止执行。你还可以考虑潜在的边缘情况以及模型应该如何处理它们,以避免意外的错误或结果。
策略四:提供少量示例
即在要求模型执行实际任务之前,提供给它少量成功执行任务的示例。
原则二:给模型时间去思考
如果模型匆忙地得出了错误的结论,您应该尝试重新构思查询,请求模型在提供最终答案之前进行一系列相关的推理。换句话说,如果您给模型一个在短时间或用少量文字无法完成的任务,它可能会猜测错误。这种情况对人来说也是一样的。如果您让某人在没有时间计算出答案的情况下完成复杂的数学问题,他们也可能会犯错误。因此,在这些情况下,您可以指示模型花更多时间思考问题,这意味着它在任务上花费了更多的计算资源。
策略一:指定完成任务所需的步骤
接下来我们将通过给定一个复杂任务,给出完成该任务的一系列步骤,来展示这一策略的效果
策略二:指导模型在下结论之前找出一个自己的解法
有时候,在明确指导模型在做决策之前要思考解决方案时,我们会得到更好的结果。
2.2局限性
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
如果模型在训练过程中接触了大量的知识,它并没有完全记住所见的信息,因此它并不很清楚自己知识的边界。这意味着它可能会尝试回答有关晦涩主题的问题,并编造听起来合理但实际上并不正确的答案。我们称这些编造的想法为幻觉。
3. 迭代提示开发
当使用 LLM 构建应用程序时,我从来没有在第一次尝试中就成功使用最终应用程序中所需的 Prompt。但这并不重要,只要您有一个好的迭代过程来不断改进您的 Prompt,那么你就能够得到一个适合任务的 Prompt。我认为在提示方面,第一次成功的几率可能会高一些,但正如上所说,第一个提示是否有效并不重要。最重要的是为您的应用程序找到有效提示的过程。

您有一个关于要完成的任务的想法,可以尝试编写第一个 Prompt,满足上一章说过的两个原则:清晰明确,并且给系统足够的时间思考。然后您可以运行它并查看结果。如果第一次效果不好,那么迭代的过程就是找出为什么指令不够清晰或为什么没有给算法足够的时间思考,以便改进想法、改进提示等等,循环多次,直到找到适合您的应用程序的 Prompt。
4. 文本概括
当今世界上有太多的文本信息,几乎没有人能够拥有足够的时间去阅读所有我们想了解的东西。但令人感到欣喜的是,目前LLM在文本概括任务上展现了强大的水准,也已经有不少团队将这项功能插入了自己的软件应用中。
4.1 文本概括实验
这里我们举了个商品评论的例子。对于电商平台来说,网站上往往存在着海量的商品评论,这些评论反映了所有客户的想法。如果我们拥有一个工具去概括这些海量、冗长的评论,便能够快速地浏览更多评论,洞悉客户的偏好,从而指导平台与商家提供更优质的服务。
## 用户的评论
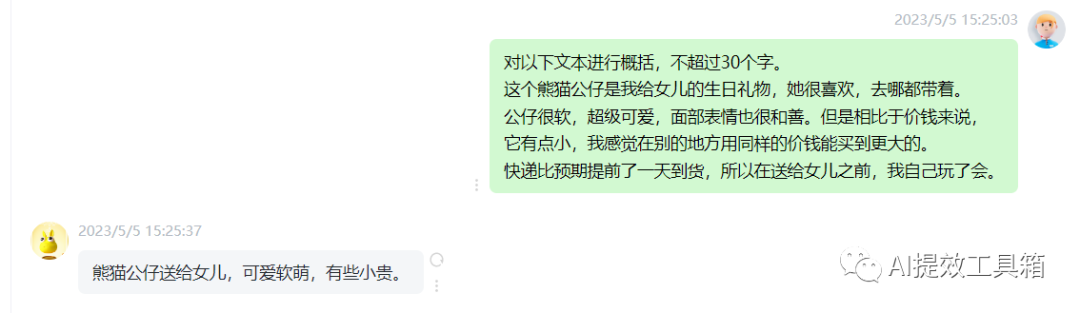
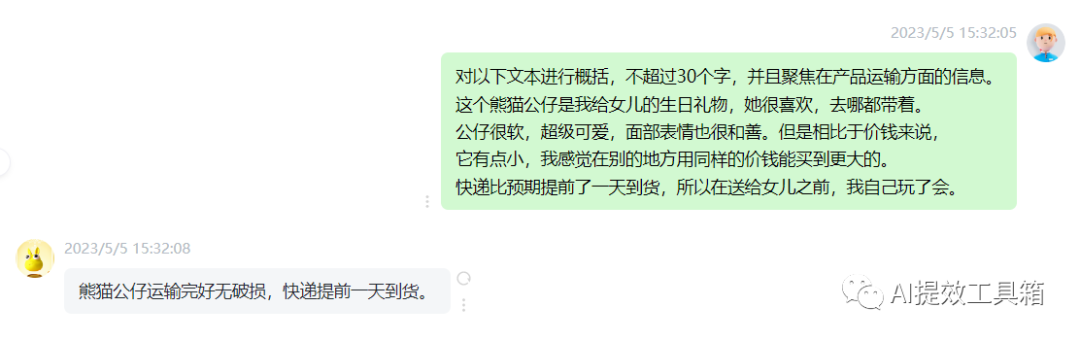
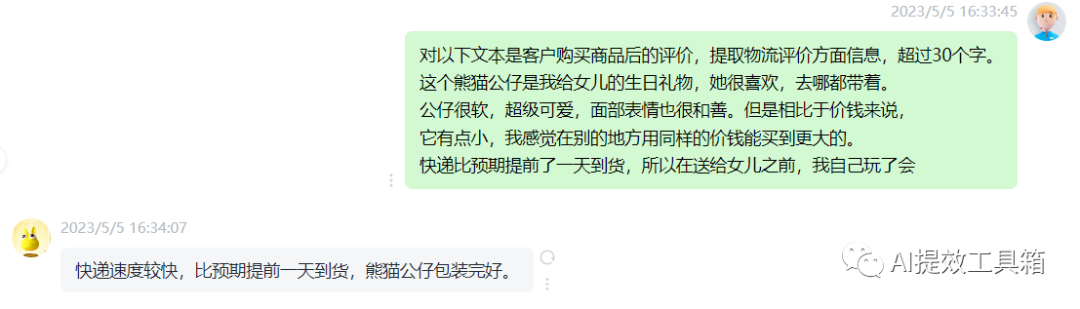
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
限制输出文本长度
我们尝试限制文本长度为最多30词,效果不错 用16个字 概括商品信息。
关键角度侧重
有时,针对不同的业务部门,我们对文本的侧重会有所不同。例如对于商品评论文本,物流会更关心运输时效,商家更加关心价格与商品质量,平台更关心整体服务体验。
我们可以通过增加Prompt提示,来体现对于某个特定角度的侧重,比如增加对产品运输方面侧重,LLM也能精准概括信息。
关键信息提取
虽然我们通过添加关键角度侧重的Prompt,使得文本摘要更侧重于某一特定方面,但是可以发现,结果中也会保留一些其他信息,有时这些信息是有帮助的,但如果我们只想要提取某一角度的信息,并过滤掉其他所有信息,则可以要求LLM进行“文本提取(Extract)”而非“文本概括(Summarize)”。
5. 推断
在本课程中,您将从产品评论和新闻文章中推断情感和主题。
5.1 情感(正向/负向)
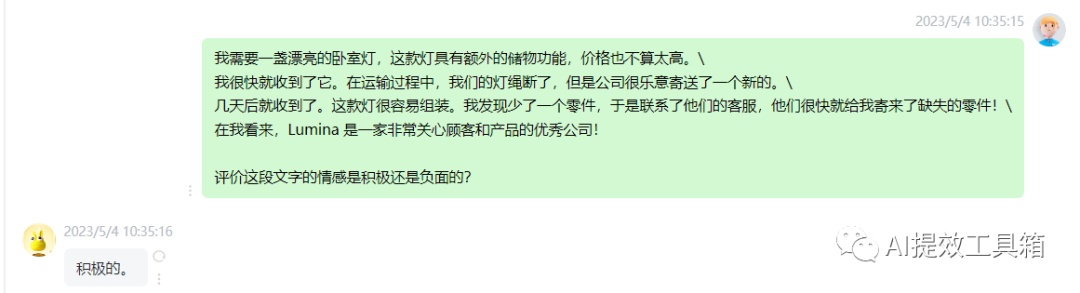
现在让我们来编写一个prompt来分类这个评论的情感。如果我想让系统告诉我这个评论的情感是什么,只需要编写 “以下产品评论的情感是什么” 这个prompt,加上通常的分隔符和评论文本等等。
然后让我们运行一下。结果显示这个产品评论的情感是积极的,这似乎是非常正确的。虽然这盏台灯不完美,但这个客户似乎非常满意。这似乎是一家关心客户和产品的伟大公司,可以认为积极的情感似乎是正确的答案。
5.2 识别情感类型
让我们看看另一个prompt,仍然使用台灯评论。这次我要让它识别出以下评论作者所表达的情感列表,不超过五个。

5.3 识别愤怒
对于很多企业来说,了解某个顾客是否非常生气很重要。所以你可能有一个类似这样的分类问题:以下评论的作者是否表达了愤怒情绪?因为如果有人真的很生气,那么可能值得额外关注,让客户支持或客户成功团队联系客户以了解情况,并为客户解决问题。

5.4 从客户评论中提取产品和公司名称
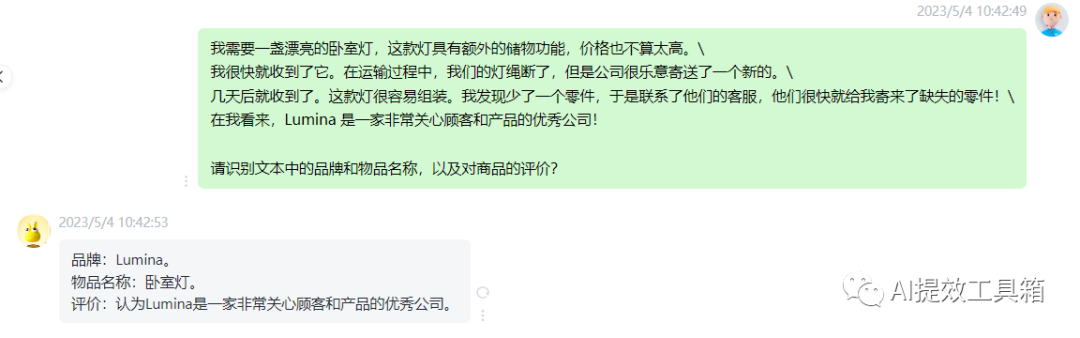
接下来,让我们从客户评论中提取更丰富的信息。信息提取是自然语言处理(NLP)的一部分,与从文本中提取你想要知道的某些事物相关。因此,在这个prompt中,我要求它识别以下内容:购买物品和制造物品的公司名称。
同样,如果你试图总结在线购物电子商务网站的许多评论,对于这些评论来说,弄清楚是什么物品,谁制造了该物品,弄清楚积极和消极的情感,以跟踪特定物品或特定制造商的积极或消极情感趋势,可能会很有用。
6. 转换
在这个笔记本中,我们将探讨如何使用大型语言模型进行文本转换任务,例如语言翻译,拼写和语法检查,语调调整和格式转换。LLM非常擅长将输入转换成不同的格式,例如多语种文本翻译、拼写及语法纠正、语气调整、格式转换等。
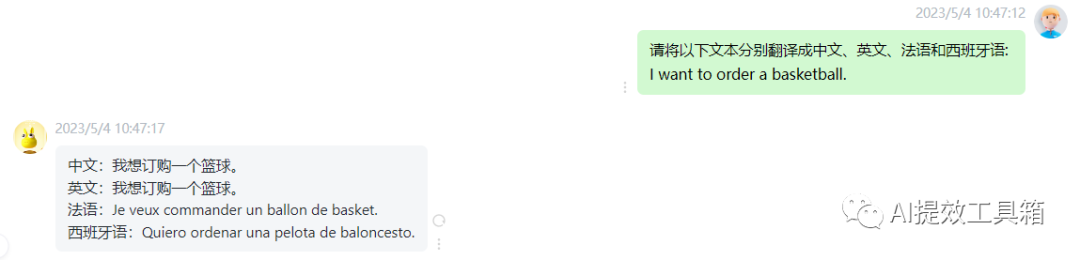
6.1 文本翻译
中文转西班牙语
![]()
识别语种
![]()
多语种翻译
![]()
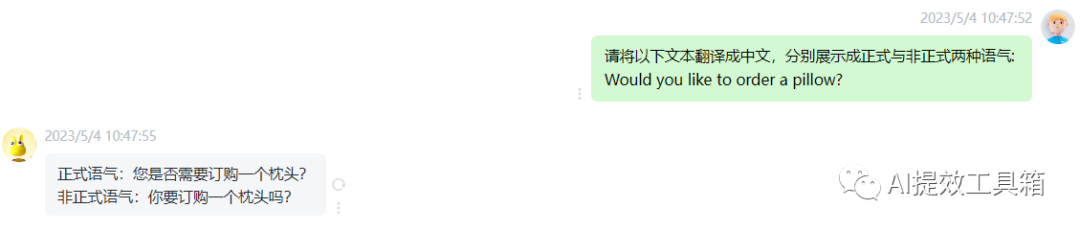
翻译+正式语气
![]()


6.2 语气/风格调整
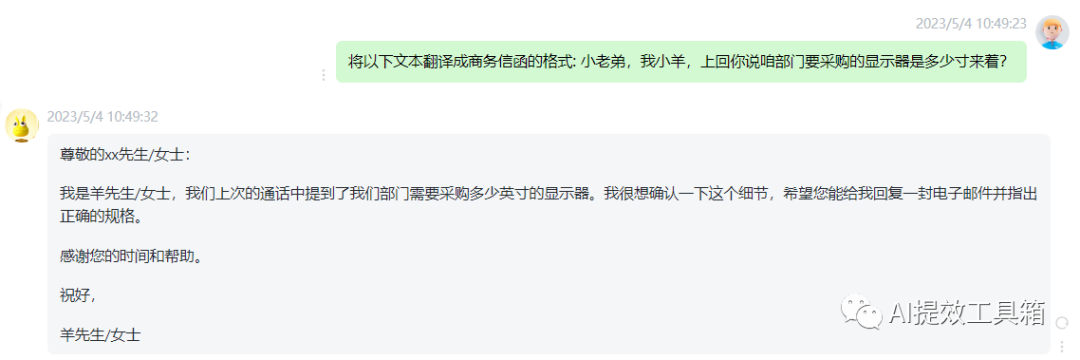
写作的语气往往会根据受众对象而有所调整。例如,对于工作邮件,我们常常需要使用正式语气与书面用词,而对同龄朋友的微信聊天,可能更多地会使用轻松、口语化的语气。
6.3 拼写及语法纠正
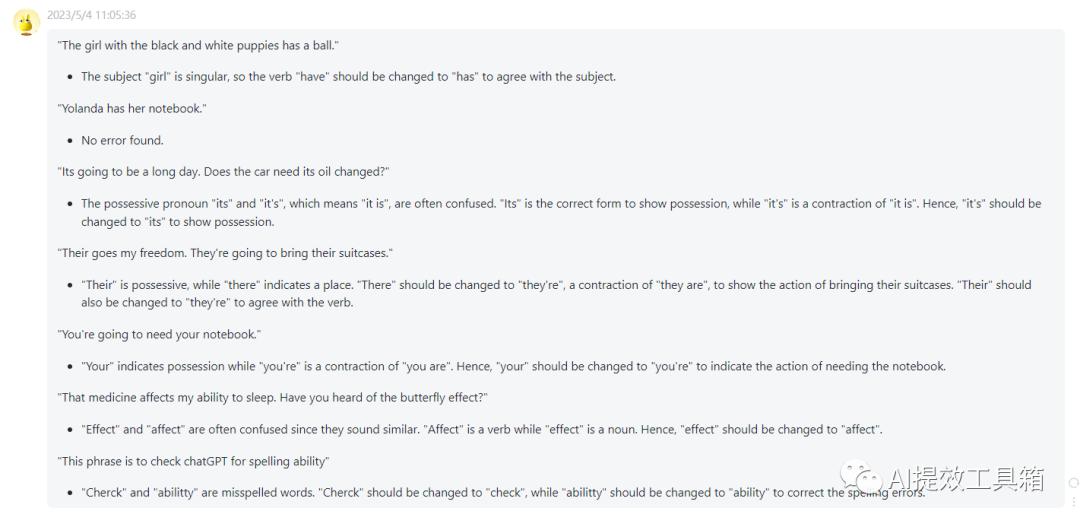
拼写及语法的检查与纠正是一个十分常见的需求,特别是使用非母语语言,例如发表英文论文时,这是一件十分重要的事情。以下给了一个例子,有一个句子列表,其中有些句子存在拼写或语法问题,有些则没有,我们循环遍历每个句子,要求模型校对文本,如果正确则输出“未发现错误”,如果错误则输出纠正后的文本。

7. 扩展
扩展是将短文本,例如一组说明或主题列表,输入到大型语言模型中,让模型生成更长的文本,例如基于某个主题的电子邮件或论文。这样做有一些很好的用途,例如将大型语言模型用作头脑风暴的伙伴。但这种做法也存在一些问题,例如某人可能会使用它来生成大量垃圾邮件。因此,当你使用大型语言模型的这些功能时,请仅以负责任的方式和有益于人们的方式使用它们。
7.1 定制客户邮件
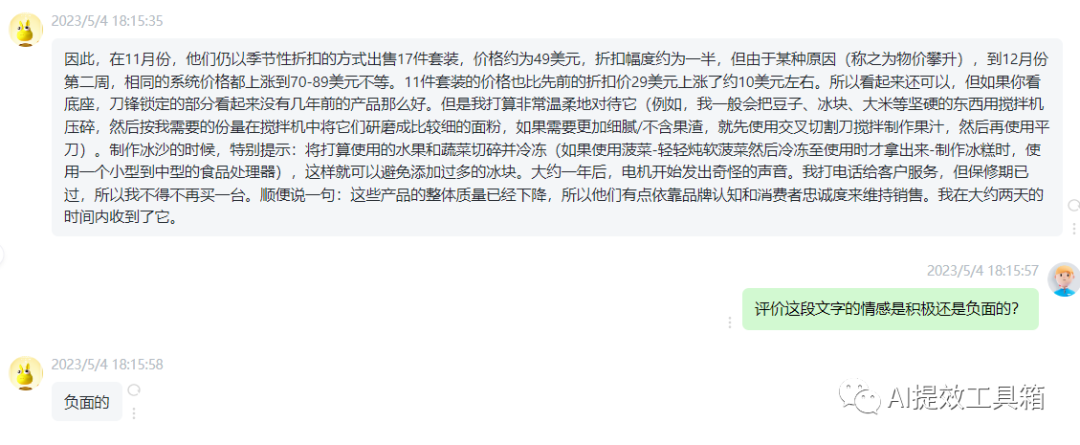
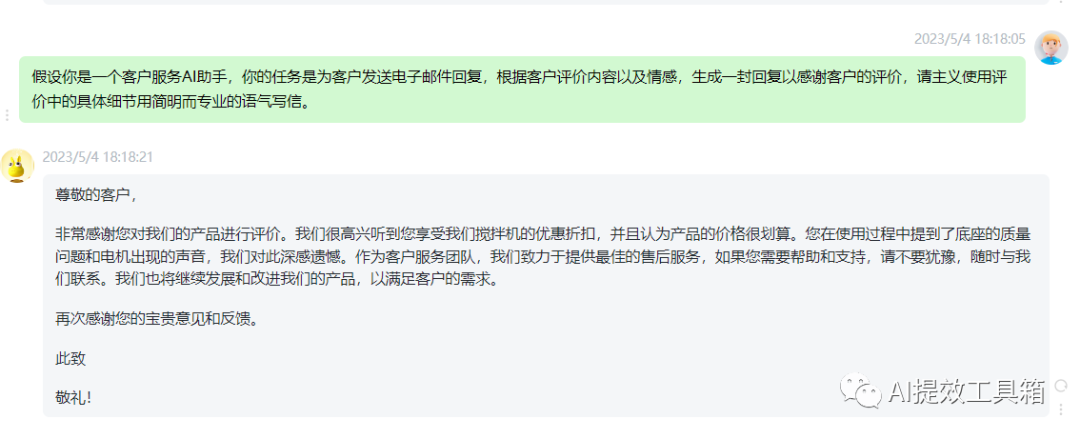
以下是客户在某电商平台上购买物品后的评价,根据上一章节方式先确定客户评价的情感属性。
根据客户评价和评论情感生成定制电子邮件。
8. 开发聊天机器人
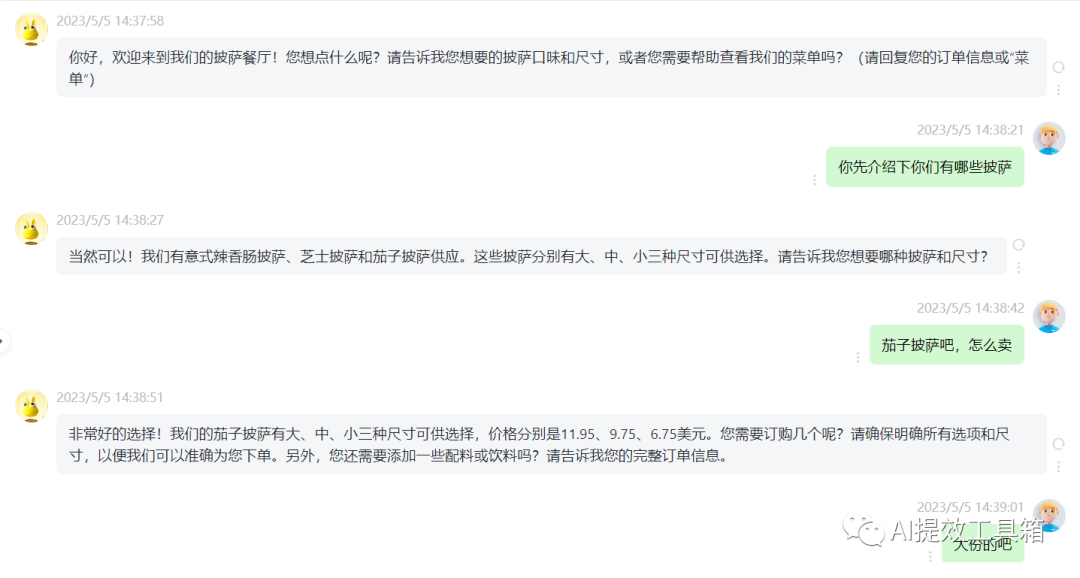
我们平时使用的 ChatGPT 网页界面,那么你发送的消息是用户消息,而 ChatGPT 回复的消息是助手消息。而系统消息是为开发者提供了一种方法,是在不让请求本身成为对话的一部分的情况下,引导助手并指导其回应,有助于设置助手的行为和角色,并作为对话的高级指示。可以想象它在助手的耳边低语,引导它的回应,而用户不会注意到系统消息。
在chatGPT的web端不能设置系统消息的模式,所以将系统消息的内容作为背景信息先喂给ChatGPT,然后开始模拟订餐机器人对话.

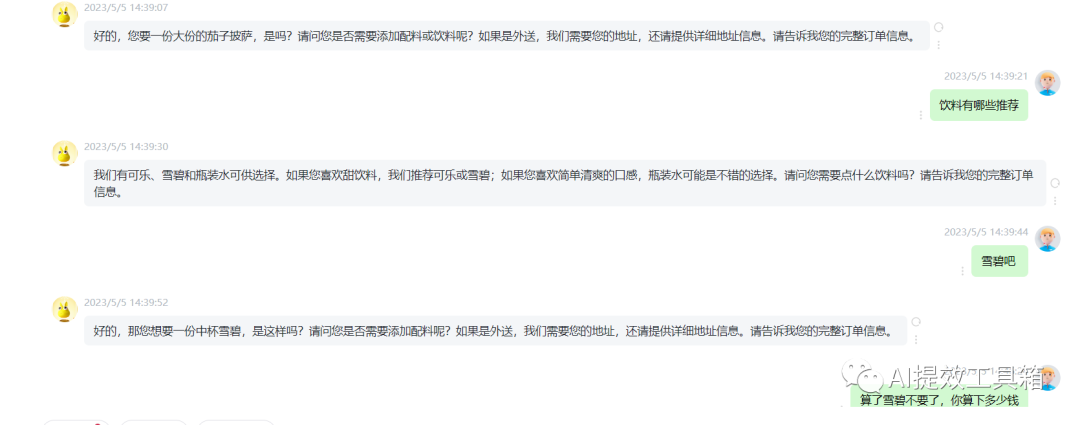
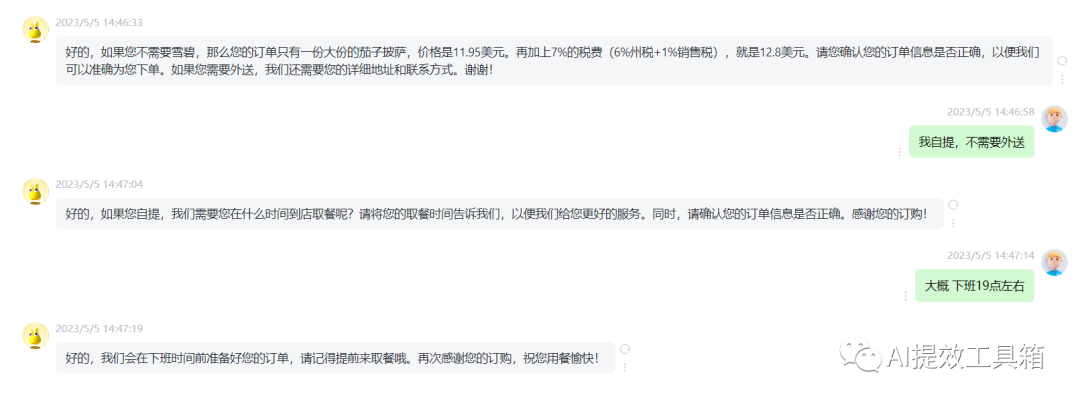
9.总结
在这个短课程中,您学到了两个关键的提示原则。编写清晰明确的说明,并在适当时给模型一些时间思考。您还了解了迭代提示开发的方法,以及为您的应用程序获取正确提示的过程是关键的。我们还介绍了许多大型语言模型的能力,这些能力对许多应用程序非常有用,特别是总结、推断、转换和扩展。您还学习了如何构建自定义聊天机器人。在这个短课程中,您学到了很多,我希望您喜欢这些材料。我们希望您能想出一些自己可以构建的应用程序的想法。请尝试一下,让我们知道您的成果。没有太小的应用程序,从一些非常小的项目开始,也可以有一些效用甚至没有什么用处,只是一些有趣的东西。是的,我发现玩这些模型非常有趣,所以去玩吧!我同意,这是一个很好的周末活动,从经验上来说。请使用您第一个项目的学习成果来构建更好的第二个项目,甚至更好的第三个项目等等。这也是我自己在使用这些模型时成长的方式。或者,如果您已经有一个更大的项目的想法,就去做吧。作为提醒,这些大型语言模型是非常强大的技术,因此我们要求您负责任地使用它们,并且只构建有积极影响的东西。是的,我完全同意。我认为在这个时代,构建人工智能系统的人可以对其他人产生巨大的影响。因此,我们所有人只能负责任地使用这些工具。我认为,基于大型语言模型的应用程序只是一个非常令人兴奋和不断发展的领域。现在,您已经完成了这个课程,我认为您现在拥有了许多知识,让您构建很少有人知道如何构建的东西。因此,我希望您也能帮助我们传播这个课程,并鼓励其他人也参加这个课程。最后,我希望您完成这个课程时玩得开心,感谢您完成这个课程。isa和我都期待着听到您构建的惊人之作。




