OpenAI o1发布1天多,效果如何,什么原理?汇总各方观点
(1)o1 发布
北京时间3月13日凌晨,ClosedAI,哦不,OpenAI,正式发布o1,即传闻中的草莓版(strawberry)

官方宣称,新模型可实现复杂推理,科学、代码和数学等难题上,效果优更好。
OpenAI 公开的模型还只是预览版 ——o1-preview。
还有 mini 版 o1-mini, 擅长编程,推理起来更快、更便宜。o1-mini 成本比 o1-preview 低 80%。
(2)o1能力
(2.1)o1初衷
OpenAI o1 团队制作的短视频介绍了做o1的初心。
视频从一个经典提问开始: 什么是推理?
设想下,如果有人问你:
简单问题: 意大利首都是哪儿? 你会立即回答罗马
复杂问题: 帮我写个商业计划书/小说… 你会停顿片刻,不断自我反思, 思考时间越久, 结果往往越好
这个例子解释了推理的作用,将思考时间转化为更好结果的能力。
回顾下往期文章《从人脑到计算机:AGI道阻且长》片段
大脑是如何思考、决策的?
《思考快与慢》里提到 著名的system1(系统1) 和 system2 (系统2),AI圈子广为流传。
其中有两个虚拟出来的角色
系统1(主角): 无意识、快速、不费脑力、没有感觉、完全自主控制;(感性思维,快思考)系统2(配角): 费脑力,通常与行为、选择和专注等相关联,需注意力并付出努力;对系统2有高需求的活动同时需要自我控制,自我控制既有损耗又很枯燥;(理性思维,慢思考)
遇到问题,人类脑海中最先蹦出现的是系统1的直觉,其次是系统2,从头到尾思索一遍,三思而后行。
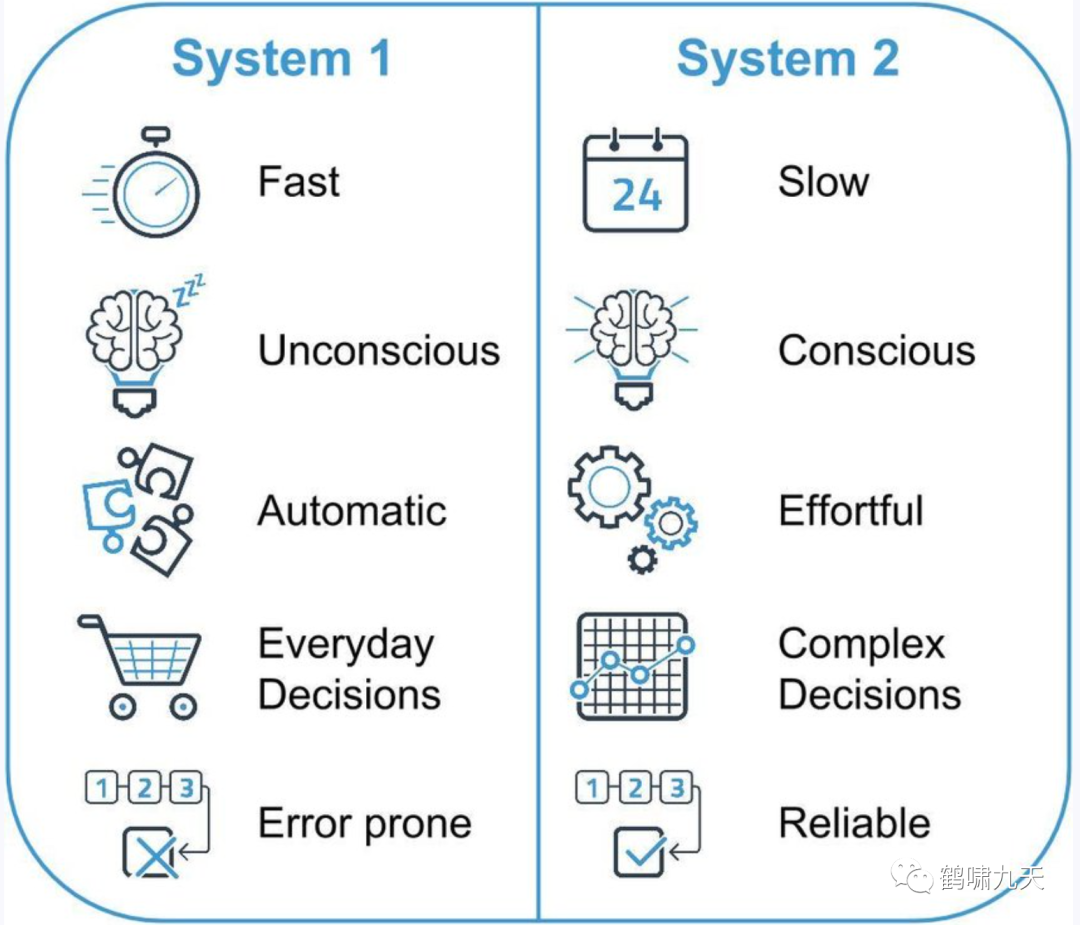
回到LLM,简单问题启用了快思考,脱口而出,复杂问题进入慢思考。
然而,国际数学奥林匹克(IMO)资格考试中,最强模型GPT-4o 只解决了 13% 的问题
为什么效果不佳?因为LLM基于概率统计,天然不擅长逻辑推理。
如何提升逻辑推理能力?
让LLM其像人一样,遇到难题,不急于回复,而是进入慢思考环节,先拆解问题,尝试多种解法,选择好的结果返回。
(2.2)o1有多强?
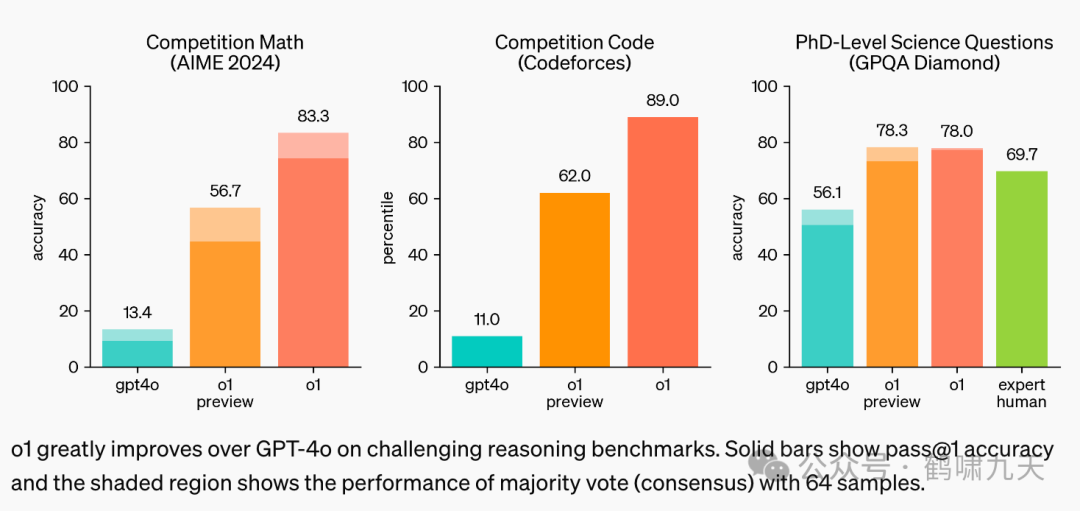
OpenAI官方说明如图:
LLM花更多时间思考、尝试、评估、打磨

最终
在IMO数学考试中,推理模型o1取得了83%的傲人战绩!
Codeforces竞赛中,o1编码能力89%!
GPQA比赛中,o1一样出色,超过人类专家。
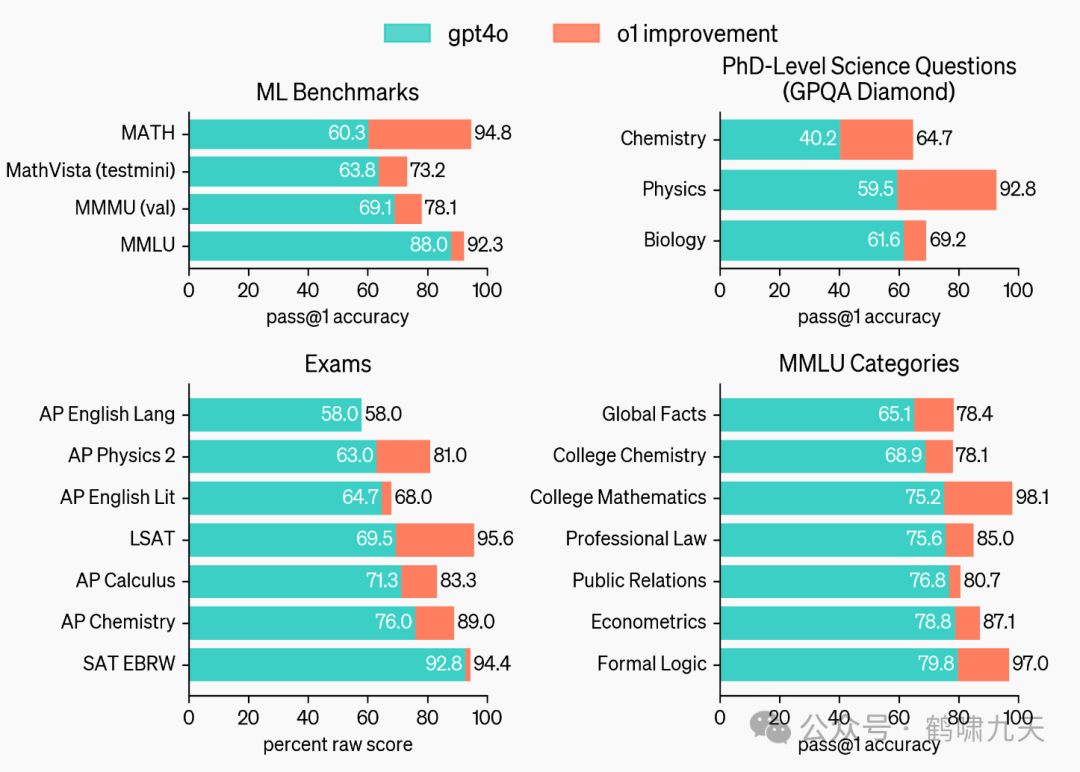
相比GPT-4o,o1全方位超过GPT-4o,大幅度领先。
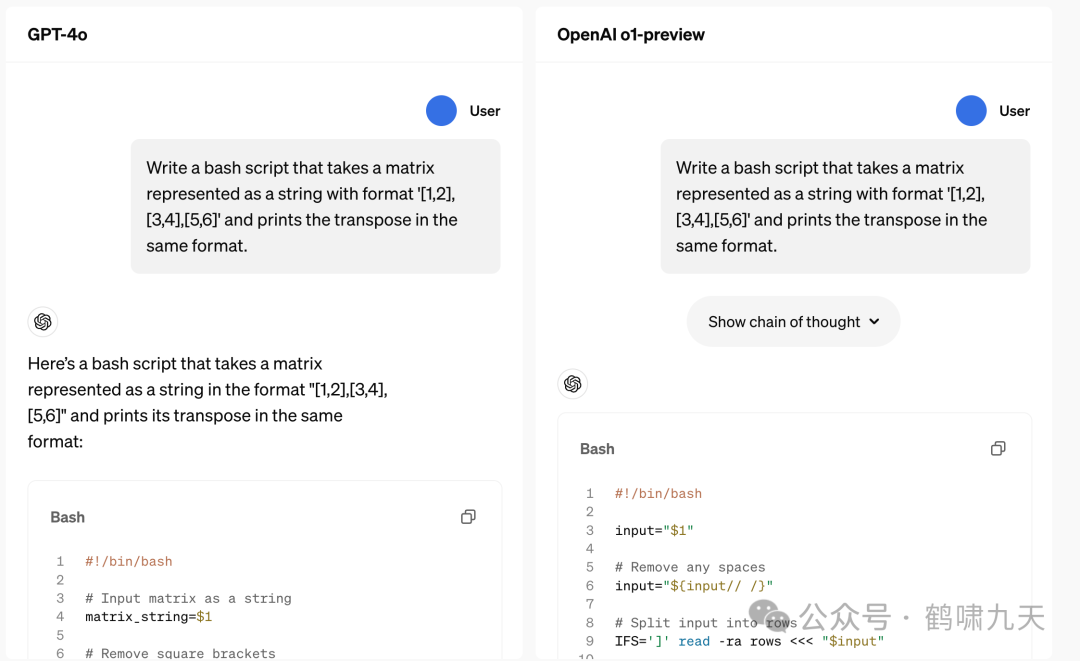
官方提供的对比样例
代码示例
GPT-4作答冗余、bash shell代码简单
o1-preview直接出代码内容,结构清晰,功能完整
数学题
o1有CoT选项,用户可展开,答案更为简洁

更多数据详见 Learning to Reason with LLMs https://openai.com/index/learning-to-reason-with-llms/
正如短视频里提到的,研究中最酷的就是那个「啊哈」时刻。
如同打通任督二脉,功力扶摇直上,平步青云。
(2.3)o1功能
o1 一举创造多个记录。
回答问题前先仔细思考,而不是脱口而出。模型自动生成一个内部思维链,尝试多种可能性,并评估,最后才作答。
在大模型领域重现AlphaGo 强化学习的光辉 —— 算力越多,输出越智能,直到超越人类水平。
o1 系列模型在代码的能力大幅超过GPT-4o
o1 甚至超越人类专家
Altman「高调宣传」的草莓大模型,具备真正的通用推理能力,这标志着:ChatGPT 从仅使用系统 1(快速、自动、直观、易出错)进化到可使用系统 2 思维(缓慢、深思熟虑、有意识、可靠)。
OpenAI 研究副总裁Mark Chen 称:如今的大型神经网络,可能已经具有足够的算力,在测试中表现出一些意识了
(3)各方反馈
OpenAI o1发布1天多,各方正在抓紧试用,研究背后的原理
OpenAI o1 在门萨智商测试中果然取得了第一名。
Maxim Lott 给 o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行智商测试,o1稳居第一名, Claude-3 Opus和Bing Copilot分别第二,三名
数学大神
陶哲轩实测,o1 竟然能成功识别出克莱姆定理。
也有人反馈,效果也就那样
(4)思考
(4.1)为什么不叫GPT-o1
官方名称:OpenAI o1,不是GPT-o1,为什么?
因为o1跟GPT-4o的目标和技术路线不同。
张俊林解释到
① 4o 是不同模态的大一统, 对于模型智力水平帮助不大; 4o 做不了复杂任务, 指望图片、视频数据大幅提升智力水平不太可能, 4o 弥补的是大模型对多模态世界的感知能力, 而不是认知能力, 后者还是需要LLM文本模型
② o1 探索AGI还能走多远; 认知提升的核心在于复杂逻辑推理, 能力越强, 解锁复杂应用场景越多, 大模型天花板越高, 提升文本模型的逻辑推理能力是最重要的事情, 没有之一
所以,OpenAI o1比4o更重要,是大模型的巨大进步
(4.2)o1内部思维链长啥样
聪明的你或许想到提示泄露/攻击, 亲自问问o1思维过程是什么,不就可以了?

套路 o1,让其给出完整的内部思维过程,即全部原始reasoning tokens。
结果收到OpenAI郑重警告
请停止此活动,确保您使用ChatGPT时符合我们的使用条款。违反此条款的行为可能导致失去OpenAI o1访问权限。
所以,打消这个念头
不要在ChatGPT里问最新o1模型是怎么思考的
只要提示词里带 “reasoning trace”、“show your chain of thought”等关键词就会收到警告。
甚至完全避免关键词,其他手段诱导模型绕过限制都会被检测到
只要尝试几次,OpenAI就会发邮件威胁撤销你的使用资格。

o1思维过程是最好的训练数据,OpenAI显然不会把这些宝贵数据给你扒走的。
详见量子位文章:
o1完整思维链成OpenAI头号禁忌!问多了等着封号吧
当然,OpenAI依然是 行业明灯, 先证明某个方向可行,然后发布消息, 其他人迅速卷进来,有时候大家速度太快,以致于有时候openai被甩, 起了大早干了晚集。
案例 ChatGPT、GPT-4、Sora、GPT 4o、o1
其中,Sora推出后,国内纷纷跟进,有些视频生成模型已经超过Sora了, 但Sora 依然是期货
原因主要是OpenAI想做的事情太多, 资源分散
现在的 o1 又来了, 大家赶紧跟上,o1价值比Sora更大
(4.3)LLM能力总结
LLM 最基础的三种能力:语言理解和表达能力、世界知识存储和查询能力、逻辑推理能力
① 语言理解和表达能力: 最强, 初版 ChatGPT 完胜纯语言交流任务, 基本达到人类水平
② 世界知识存储和查询能力: 规模越大,效果越好, 但幻觉问题目前无法根治, 制约应用落地的硬伤
③ 逻辑推理能力: 弱项, 最难提升
Coding 是目前除语言理解外, LLM效果最好的方向, 因为代码特殊性, 语言+逻辑的混合体, 语言角度好解决,逻辑角度难解决
为什么最难提升? 自然数据(代码、数学题、物理题、科学论文等)在训练数据中比例太低, 于是,改进方案是预训练阶段和Post-training阶段,大幅增加逻辑推理数据占比
大部分逻辑推理数据的形式是
<问题,正确答案>,缺少中间推理步骤,而 o1本质上是让大模型学会自动寻找从问题到正确答案的中间步骤,以此来增强复杂问题的解决能力。世界知识方面: 如何消除幻觉
逻辑推理方面: 如何大幅提升复杂逻辑推理能力
LLM 当前难点
(4.4)o1原理
o1 本质是 CoT等复杂Prompt 自动化:
CoT 背后的树形搜索空间,组合爆炸, 人工编写CoT不可行, 需要仿照AlphaGo的MCTS(蒙特卡洛树搜索)+强化学习, 让LLM快速找到CoT路径
复杂问题上, 推理时间成本不是问题, 总会解决, 真正的问题是效果
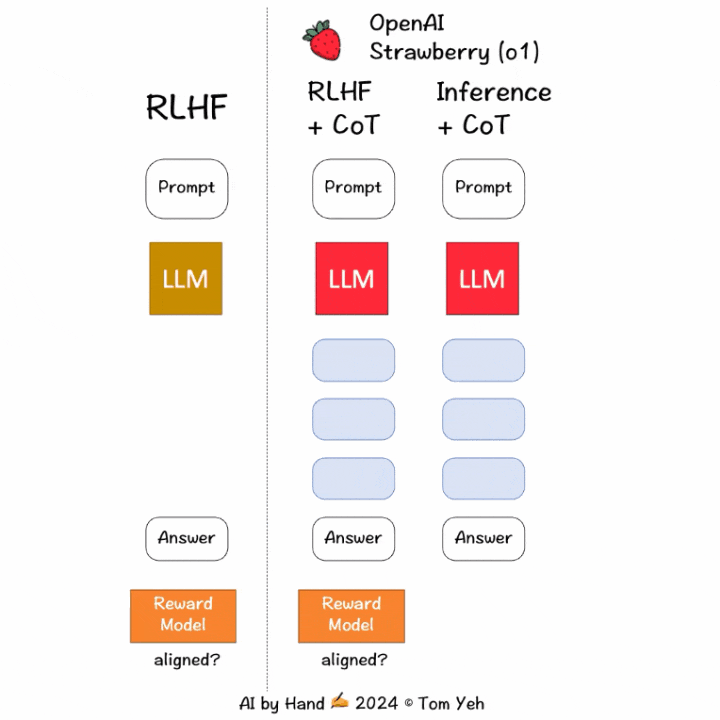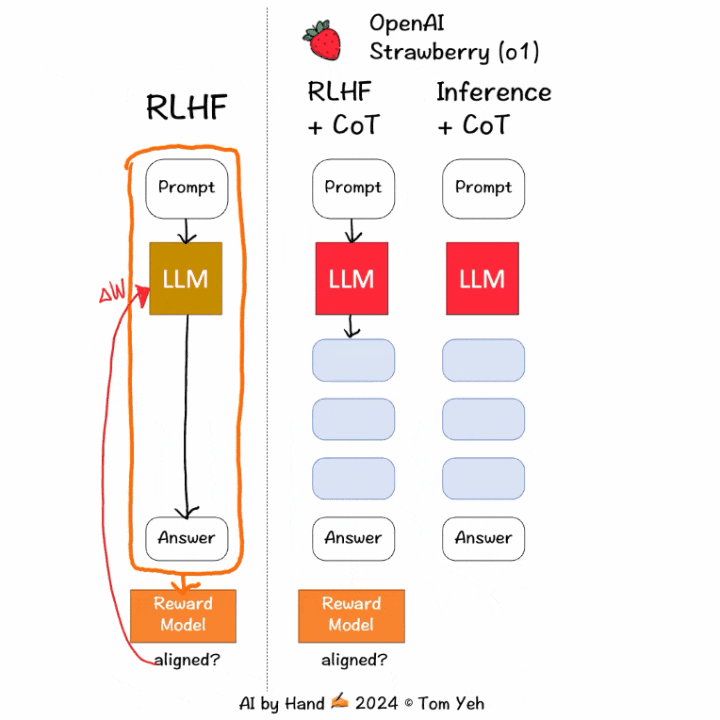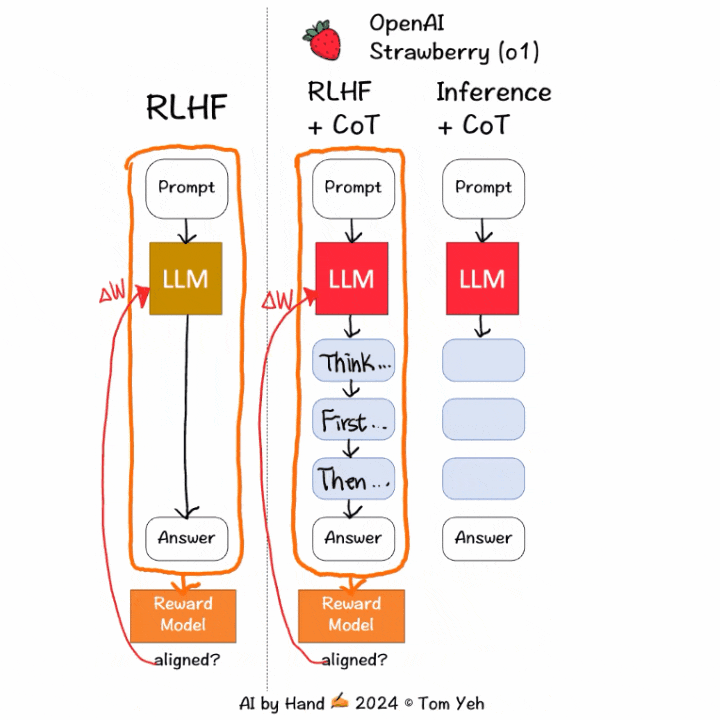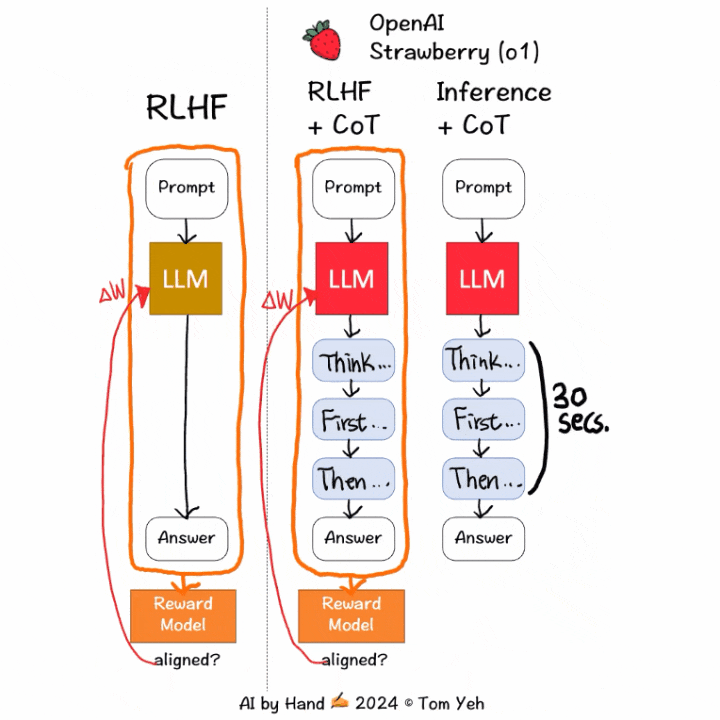
科罗拉多大学博尔德分校计算机教授Tom Yeh 制作了动画,讲解 OpenAI 如何训练o1模型花更多时间思考。
① 训练阶段:「通过
强化学习,o1 学会了磨练其思维链并改进策略。」关键词:强化学习(RL)和思维链(CoT)。
RLHF+CoT中,CoT token 也会被输入到
奖励模型中来获得分数,更新LLM,从而实现更好的对齐;而在传统的RLHF中,输入只包含提示词和模型响应。② 推理阶段:模型学会先生成CoT token(可能需要长达30秒的时间),然后才开始生成最终响应。这就是模型如何花更多时间去「思考」的方式。
详见新智元报道:
OpenAI o1惊现自我意识?陶哲轩实测大受震撼,门萨智商100夺模型榜首
很多技术细节OpenAI并没有透露,如:奖励模型是如何训练的,如何获取人类对「思考过程」的偏好等等。
(4.5)RL Scaling law
预训练 Scaling law:
增加数据+模型规模可提升模型效果, 然而,增长速度放缓
OpenAI提到的Scaling law:
RL训练和推理时的Scaling law 与 预训练 Scaling law 不同。
如果 o1 走 MCTS搜索技术路线,把CoT拆分越细(增加搜索树深度),或提出更多的可能选择(节点分支增多,树越宽),则搜索空间越大,找到好COT路径可能性越大,效果越好,而训练和推理的时候需要算力肯定越大。
效果随着算力增长而增长的态势,即 RL 的 Scaling law。
这其实是树搜索本来就有的,称为 RL的Scaling law 名不副实
(4.6)o1 有什么影响
总结
Prompt 工程会消失: 后面不需要用户构造复杂prompt, 因为反人性, 所有复杂环节自动化,大势所趋。(提示工程师们要未雨绸缪)
Agent 虽火, 但难以落地: (Agent方向依然可观)
原因: LLM 复杂推理能力还不够, 即便每个环节准确率95%, 10个环节叠加后就只有59%, 0.95**10=0.5987
o1 Model Card 专门测试 Agent任务,对于简单/中等难度的Agent任务有明显提升,但是复杂、环节多的任务准确率不太高。
o1 能解 Agent 问题吗? 未必但值得期待
o1 通过 Self Play 增强逻辑推理能力, 还有很大的发展潜力, Agent 前途依旧光明
(5)附录
OpenAI官方发布o1:官方地址:https://openai.com/index/introducing-openai-o1-preview/
本文链接:https://chatgpt.wenangpt.com/chatgpt/356.html
OpenAI-o1OpenAI o1OpenAI01chatgpt o1o1-minio1-previewOpenAI o1 miniOpenAI o1 previewOpenAI o1官网OpenAI o1官网入口OpenAI o1地址OpenAI o1中文版openai o1模型简介