ChatGPT到底是什么?
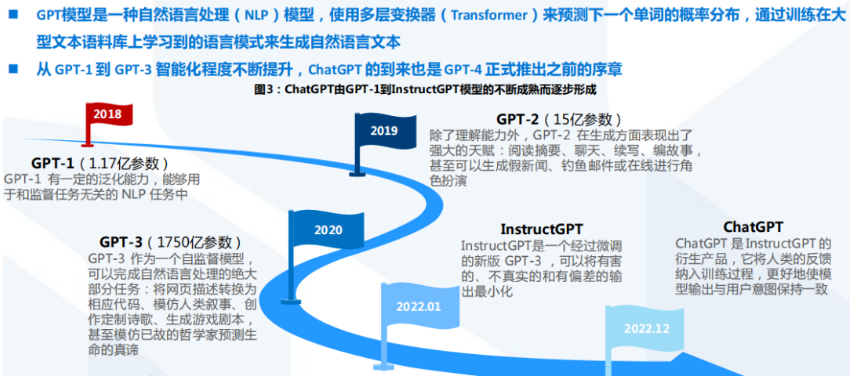
本期和大家聊一下时下比较火热的ChatGPT,关于账号的使用和介绍的视频,最开始之前自己也有密切的关注略知一二。首先这个东西他不是凭空出现的,其实在这之前就有过几代,比如说GPT4和GPT3,然后就是去年的2022年的12月份发布了最新的,也就是现在疯传的ChatGPT。目前是被微软所收购,据说投资也不少,所以这个前景大家是可以去期待一下的。现在就向大家解释一下ChatGPT这个缩写,它的一个大致是什么含义:首先 Chat 就是我们说的沟通交流的意思,所以它本质就是一个沟通交流的软件;这个G其实是generative的缩写,也就是生成式和生产式的意思;这个P它代表的是一个复合词,是pre-trained,就是经过提前训练的;最后这个T就是transformer,表示转换的意思。其实我们目前市面上很多产品都是通过运用这个transformer的思想来完成的(就是利用转换的思想,比如说代码转换成app或者一段话)
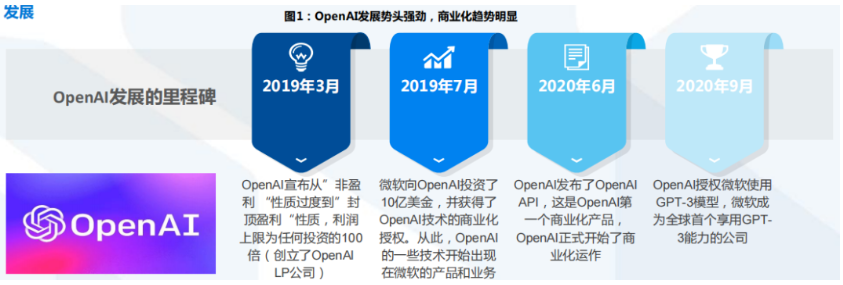
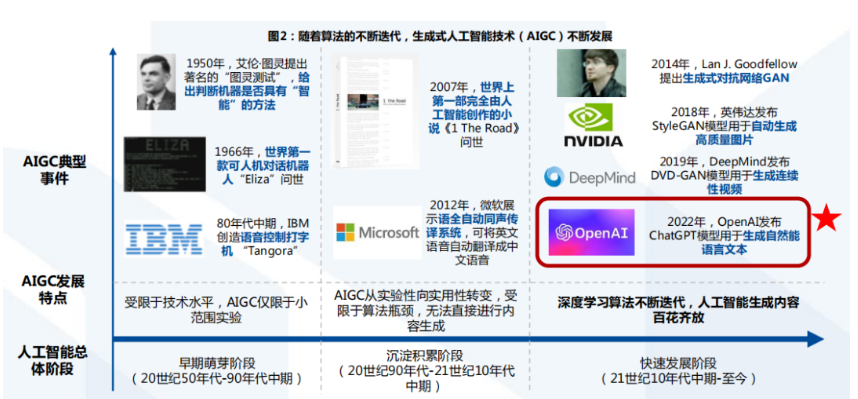
OpenAI 成立于 2015 年 12 月,是所处于美国旧金山的一个人工智能研究实验室,由非营利性的 OpenAI Inc.及其营利性的子公司 OpenAI LP 组成。OpenAI 开展人工通用智能(AGI)研究,为了确保 AI 能够造福全人类,OpenAI 提供了一个基于 AI 的开发和研究框架,这也是其名字的来源(开放 AI 能力)。利用 OpenAI 的平台,客户可以快速提升开发技能并获取 AI 领域的专业知识,这有助于安全有效的通用人工智能(AGI)技术的发展。OpenAI 开发、维护和训练了一批可用于通用活动的 AI 模型,包括写作、阅读、编程和图像处理等,OpenAI 始终相信 AGI 对我们日常生活的影响将远远超过早期的 AI 技术。马斯克、奥特曼和其他投资者于 2015 年 12 月宣布创建 OpenAI,并承诺向该项目投入超过 10 亿美元。通过公布其专利和研究成果,OpenAI 将与其他组织和研究人员“自由互动”。“OpenAI Gym”的公测版本于 2016 年 4 月 27 日发布,这是一个加强OpenAI 研究领域的平台。2016 年 12 月 5 日,OpenAI 发布了“Universe”,这是一个用于开发和测试 AI 的平台,智能能力可以覆盖全球的网站、游戏和其他应用程序。2019 年 3 月 11 日,OpenAI 宣布从“非盈利(non-profit)”性质过度到“有限盈利(capped for profit)”,利润上限为任何投资的 100 倍(创立了 OpenAI LP 公司)。也是在 2019 年,微软向 OpenAI 投资了 10 亿美金,并获得了 OpenAI 技术的商业化授权。从此,OpenAI 的一些技术开始出现在微软的产品和业务上。不过,OpenAI 与微软的合作其实从 2016 年就开始,2016 年,微软的云服务 Azure 为 OpenAI 提供了大规模实验的平台。Azure 彼时已经为他们提供了带有 InfiniBand 互连的 K80 GPU 的算力资源,以优化深度学习的训练。2020 年 9 月 22 日,OpenAI 开始授权微软使用他们的 GPT-3 模型,也是全球首个可以享受 GPT-3 能力的公司。2020 年 6 月 11 日,OpenAI 发布了 OpenAI API,这也是 OpenAI 第一个商业化产品。官方解释了,他们认为开发商业产品是确保 OpenAI 有足够资金继续投入 AI 研究的有效手段。自此,OpenAI 也正是开始商业化运作。官方也解释了,使用 API 的方式提供模型而不是开源模型也将降低模型的使用门槛,毕竟对于中小企业来说,部署强大的 AI 模型所需要的成本可能更高。2016 年至今,OpenAI 发布了很多人工智能相关的技术,从工具到算法到论文到模型,都有涉及。2016 年 4 月 27 日,OpenAI 发布了他们的第一个项目——OpenAI Gym Beta,这是一个用来开发和比较不同强化学习算法的工具。2017 年 5 月 24 日 , OpenAI 开 源 了 一 个 重 现 强 化 学 习 算 法 的 工 具 ——OpenAI Baselines。目标是提供用于正确的强化学习算法实现的一些最佳实践,以帮助大家提高强化学习的研究效率。2018 年 6 月 11 日,OpenAI 公布了一个在诸多语言处理任务上都取得了很好结果的算法,即著名的 GPT,这也是该算法的第一个版本。GPT 是第一个将 transformer 与无监督的预训练技术相结合,其取得的效果要好于当前的已知算法。这个算法算是OpenAI 大语言模型的探索性的先驱,也使得后面出现了更强大的 GPT 系列。同2018 年 6 月份,OpenAI 的 OpenAI Five 已经开始在 Dota2 游戏中击败业余人类团队,并表示在未来2个月将与世界顶级玩家进行对战。OpenAI Five使用了256个P100GPUs 和 128000 个 CPU 核,每天玩 180 年时长的游戏来训练模型。在随后的几个月里 OpenAI Five 详情继续公布。在 8 月份的专业比赛中,OpenAI Five 输掉了 2场与顶级选手的比赛,但是比赛的前 25-30 分钟内,OpenAI Five 的模型的有着十分良好的表现。OpenAI Five继续发展并在 2019 年 4 月 15 日宣布打败了当时的 Dota2世界冠军。2019 年 2 月 14 日,OpenA 官宣 GPT-2 模型。GPT-2 模型有 15 亿参数,基于 800 万网页数据训练。2019 年 11 月 5 日,15 亿参数的完整版本的 GPT-2 预训练结果发布。2019 年 3 月 4 日,OpenAI 发布了一个用于强化学习代理的大规模多代理游戏环境:Neural MMO。该平台支持在一个持久的、开放的任务中的存在大量的、可变的代理。2019 年 4 月 25 日,OpenAI 公布了最新的研究成果:MuseNet,这是一个深度神经网络,可以用 10 种不同的乐器生成 4 分钟的音乐作品,并且可以结合从乡村到莫扎特到披头士的风格。这是 OpenAI 将生成模型从自然语言处理领域拓展到其它领域开始。2020年4 月14 日,OpenAI 发布了 Microscope,这是一个用于分析神经网络内部特征形成过程的可视化工具,也是 OpenAI 为了理解神经网络模型所作出的努力。2020 年 5 月 28 日,OpenAI 正式公布了 GPT-3 相关的研究结果,其参数高达 1750亿,这也是当时全球最大的预训练模型,同年 9 月,GPT-3 的商业化授权给了微软。2020年6 月17 日,OpenAI 发布了 Image GPT 模型,将 GPT 的成功引入计算机视觉领域。2021 年1 月 5 日,OpenAI 发布 CLIP,它能有效地从自然语言监督中学习视觉概念。CLIP 可以应用于任何视觉分类基准,只需提供要识别的视觉类别的名称,类似于GPT-2 和 GPT-3 的 "zero-shot "能力。2021 年 1 月 5 日,OpenAI 发布了 DALL·E 模型,其为 120 亿个参数的 GPT 3 版本,它被训练成使用文本-图像对的数据集,从文本描述中生成图像。2021年8 月10 日,OpenAI 发布了 Codex。OpenAI Codex 同样是 GPT 3 的后代;它的训练数据既包含自然语言,也包含数十亿行公开的源代码,包括GitHub 公共存储库中的代码。OpenAI Codex 就是Github Coplilot 背后的模型。2022年1月27日,OpenAI 发布了 InstructGPT。这是比 GPT 3 更好的遵循用户意图的语言模型,同时也让它们更真实,且 less toxic。2022 年 3 月 15 日,OpenAI 新版本的 GPT-3 和 Codex 发布,新增了编辑和插入新内容的能力。2022 年 4 月 6 日,DALL·E2 发布,其效果比第一个版本更加逼真,细节更加丰富且解析度更高。2022 年 6 月 23 日,OpenAI 通过视频预训练(Video PreTraining,VPT)在人类玩Minecraft 的大量无标签视频数据集上训练了一个神经网络来玩 Minecraft,同时只使用了少量的标签数据。通过微调,该模型可以学习制作钻石工具,这项任务通常需要熟练的人类花费超过 20 分钟(24,000 个动作)。它使用了人类原生的按键和鼠标运动界面,使其具有相当的通用性,并代表着向通用计算机使用代理迈出了一步。2022 年 9 月 21 日,OpenAI 发布了 Whisper,这是一个语音识别预训练模型,结果逼近人类水平,支持多种语言。
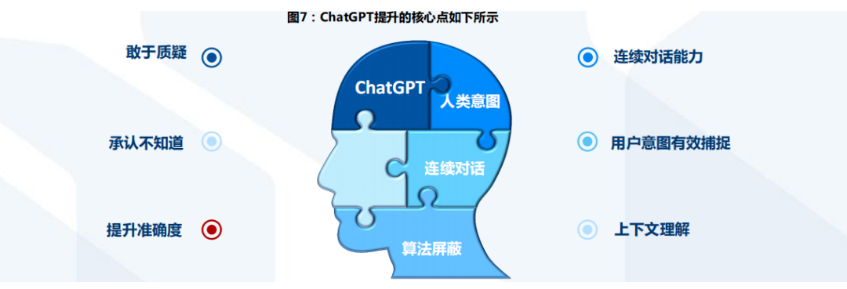
短期来看,ChatGPT仍存在诸多不足。等待解决的问题主要有两方面: 合规性性问题和技术性问题。
□合规性问题1. ChatGPT产生的答复是否产生相应的知识产权?2. ChatGPT进行数据挖掘和训练的过程是否需要获得相应的知识产权授权?3. ChatGPT是基于统计的语言模型,这一机制导致回答偏差会进而导致虚假信息1. ChatGPT的回答可能过时,因为其数据库内容只到2021年,对于涉及2022年之后,或者在2022年有变动的问题无能为力2. ChatGPT在专业较强的领域无法保证正确率,即使在鸡兔同笼此类初级问题中仍然存在错误,并且英文回答和中文回答存在明显差异化3. ChatGPT对于不熟悉的问题会强行给出一定的答案,即使答案明显错误,依然会坚持下去,直到明确戳破其掩饰的内容,会立马道歉,但本质上会在不熟悉的领域造成误导好啦,本期分享的内容就到这里了。内容源自学院拓展,个人整理成文章分享,有什么不全的地方或者小伙伴知道没有写上的,欢迎评论区留言补充讨论。
本文链接:https://chatgpt.wenangpt.com/chatgpt/284.html