ChatGPT已上线五个月,然而还是有不少人未能掌握其使用技巧。
驾驭ChatGPT的难点,在于Prompt(提示词)的编写。OpenAI 创始人明确指出:“能够出色编写Prompt跟聊天机器人对话,是一项能令人惊艳的高杠杆技能。”
目前,你看到的几乎所有AI工具助手,本质上都是通过良好的Prompt实现的。只要你的Prompt够出色,ChatGPT就可以快速完成爬虫脚本、金融数据分析、文案润色与翻译等任务,并且做得比一般人更优秀。
如果你未真正掌握Prompt应用,就无法发挥ChatGPT的威力。举例来说,有很多人还不知道,在给 ChatGPT 提供代码或者翻译文本时,需要使用引号分隔符帮助ChatGPT理解指令的内容结构,以确保其输出更准确的结果。
为了帮助大家能更好的掌握 Prompt 工程,DeepLearning.ai 创始人吴恩达(前百度/谷歌AI部门负责人)与 OpenAI 开发者Iza Fulford联手推出了一门面向开发者的技术教程:《ChatGPT 提示工程》。

虽然吴恩达老师的课程是英文讲授,且面向开发者,但该课程仍然值得每一名使用ChatGPT的同学去认真学习。
在这门课程中,您将学习到:
大语言模型的底层原理
Prompt的编写原则
Prompt的优化思路
大语言模型的能力:总结、推理、转换和扩张

课程内容
该课程1个多小时,一共9个章节,包括课程介绍、Prompt原则、Prompt优化、大语言模型的实践应用等。
下面,我将和大家展开解读:

核心内容:大语言模型的分类
基础大语言模型(Base LLM):
底层逻辑是“单字接龙”,即大模型基于互联网或其他来源的大数据进行海量训练,学习总结规律,提示上文,模型生成下一个最有可能的单词,并且通过自回归生成,即可回复任意长文。
指令调整型大语言模型(Instruction Tuned LLM):
首先使用经过大数据训练的基础大语言模型,使用输入/输出指令对模型进行微调,即给它投喂符合人类规范的问答范例,以让它更好的遵循指令,输出对应指令的结果。
这里,通常使用一种叫做RLHF(人类反馈强化训练)的技术进一步优化,以使系统更好的遵循指令。
指令调整型大语言模型更有可能输出有益、诚实和无害的文本,大多是应用都是基于指令调整型大语言模型,但仍然有可能输出错误,所以需要我们投喂数据和相应指令进行优化调整。

核心内容:2个Prompt编写原则和LLM的短板
原则一:清晰而具体的指令
策略1:妙用分割符号,如" "、```、---、<>,它可以避免模型误解你的指令内容。
策略2:要求结构化输出,如直接要求它以html、json、Markdown等格式输出,这样可以更好地使用大模型的输出内容,加快下游应用的开发速度。
策略3:要求模型检测是否满足指令条件,帮助模型输出更符合你需要的结果。
策略4:提供样本数据,定义输出内容的格式。由于大模型能力强大,只需要提供少量的样本数据,就能完成“学习”的过程,输出符合你需求的内容。
原则二:给模型足够的时间思考
策略1:让模型按步骤来解答,把自己的大目标,拆分成一个个小问题,引导模型一步步回答。第一步你应该怎么答,第二步你应该怎么答,最后……
策略2:让模型自己推导出过程,而不仅仅是结论,有时候太快给出结论容易出错。
LLM的短板:模型幻觉
大语言模型和搜索引擎非常不同,大语言模型并不是根据指令,去数据库比对、调用、拼接信息,然后给你答案;而是基于大数据训练时所学规律(通用模型),根据上文,逐字生成给你的答案,
搜索引擎无法给出没被数据库记忆的信息,但大语言模型可以,还可以创造不存在的文本。这是它的长板,也是它的短板。
它可以用学习到的规律来回答,但这也就意味着,当出现“实际不同但碰巧符合同一规律”的内容,模型就有可能混淆它,最直接的结果是:现实中不存在的内容,刚好符合它从训练材料中学到的规律,那么ChatGPT就有可能对不存在的内容进行合符规律的混合捏造。
这就是为什么有时候我们问他一些事实性或新闻内容时,它可能会一本正经的胡说八道。
我们把大语言模型的这种短板,叫做模型幻觉。
为了尽可能避免模型产生幻觉,我们需要告诉模型聚焦特定方向,或者给模型提供相关资料,再根据相关资料来回答问题。
尽管如此,模型幻觉仍然难以避免,这也是目前模型研究领域正在努力的方向。

核心内容:
类似于机器学习的过程,我们通常无法在第一次尝试时就获取到想要的答案,Prompt的编写通常也需要有这样一个迭代优化的过程:
编写Prompt(要求明确且具体)
尝试运行并获取结果
分析结果为什么没有获得预期输出
进一步细化与调整Prompt
重复这个过程,直到得到合适的Prompt
成为一个高效的Prompt工程师的关键,不在于掌握完美的Prompt,而是有一个良好的过程来探索适用于自己应用程序的Prompt。

核心内容:大语言模型具备概括文章/生成摘要的总结能力,并且介绍了一个具体的应用场景——总结商品评论。

核心知识:大语言模型具备分析推理能力,可以用于识别文本情感、提取信息和推断主题等工作场景。

核心知识:大语言模型非常擅长将其输入转换为不同的格式,可以用于翻译、拼写检查/语法纠正以及结构化输出(JSON)等工作。

核心知识:大语言模型具备扩充能力,就是将简短文本片段扩充为更长文本的能力,在写邮件或写论文的时候会经常用到,也常有人将其用于头脑风暴。

核心知识:
定制聊天机器人的原理:通过定义聊天格式或指定任务内容的方式,构建定制化的聊天机器人。
应用场景(披萨餐厅订单机器人):
步骤1:构建GUI
步骤2:提供上下文
步骤3:收集订单信息
步骤4:生成订单摘要,发送到订购系统

核心内容:
这门短期课程主要介绍了两个关键的提示原则:编写清晰明确的指令和在适当的时候给模型一些时间来思考。
同时,还学习了迭代提示开发的过程,以及如何构建自定义聊天机器人。
此外,课程还介绍了大型语言模型的几个有用功能,包括摘要、推断、转换和扩展。
最后,强调了使用这些工具时需要负责任,只构建对他人有积极影响的应用。完成这门课程后,学习者可以尝试构建自己的应用,并将所学知识传播给他人。
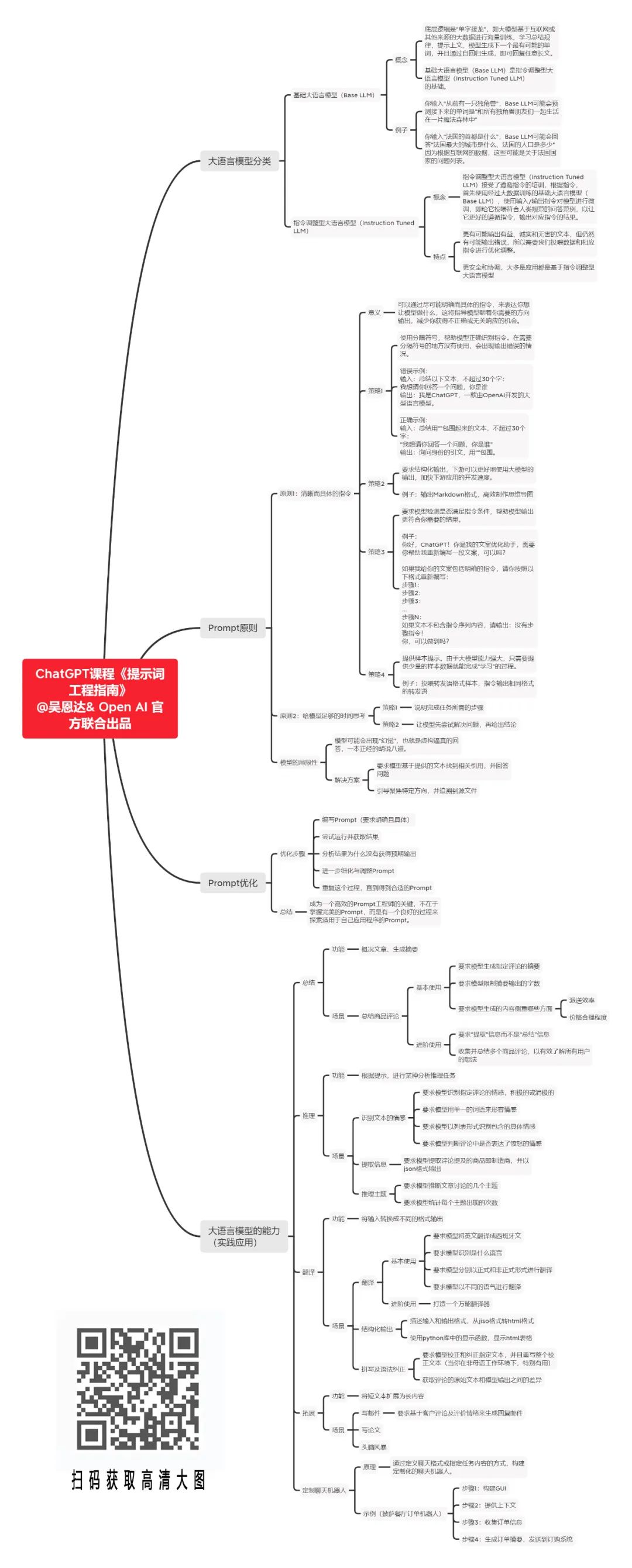
最后的最后,我们将本文的所有内容总结成了以下这张思维导图,需要高清大图,扫码下图二维码即可获取。
对课程感兴趣,想直接线上观看学习的同学,也可以上DeepLearning.ai的官网免费观看:
https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/

我们的ChatGPT&AI学习交流社群
【AI创意圈】重磅来袭
赶快扫码加入吧
和我们一起拥抱AI 掌握AI
提高工作效率 少加班!
👇

扫码领券 马上加入
名额有限 先到先得

ChatGPT新手注册攻略!保姆级教程!
Midjourney注册及入门教程!包学包会!
ChatGPT+Xmind,炸裂了!3分钟搞定思维导图!